Curated library
Videos
Watch the clearest companion videos without browsing everything at once. Pick a path, continue where you left off, or use the filters when you know what you need.
Viewing learning path: BuilderShow all
 4 minutes
4 minutesIntroducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings
Understand why multilingual embeddings matter for private internal search and where local retrieval can reduce data-exposure risk.
 18 minutes
18 minutesAWS re:Invent 2025 - Implementing Human-in-the-Loop Controls for Multi-Agent AI Systems (CNS428)
See how approval gates can be implemented as explicit workflow checkpoints rather than informal manual review after something goes wrong.
 7 minutes
7 minutesUnlock Better RAG & AI Agents with Docling
Understand why document parsing, structure preservation and ingestion quality gates matter before building RAG over PDFs and mixed file formats.
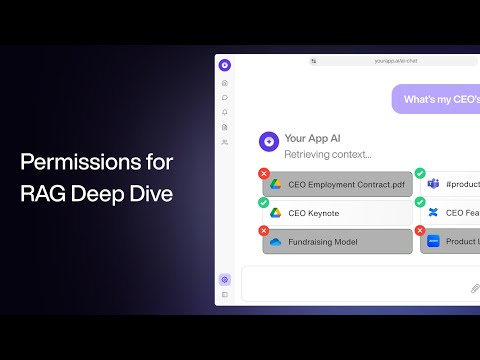 20 minutes
20 minutesPermissions & Access Control for RAG - a Deep Dive Tutorial
Evaluate practical access-control patterns for company knowledge RAG before indexing sensitive internal documents.
 48 minutes
48 minutesHow to Build Reliable AI Agents (Context + Evals Explained) | Tobias Leong, Axium
Design AI workflows around context, evals and observability so production failures can be named, measured and fixed.
 42 minutes
42 minutesVertical AI Agents Could Be 10X Bigger Than SaaS
Assess when vertical AI agents create real defensibility and when they are only thin wrappers.
 34 minutes
34 minutesHow AI is Reinventing Software Business Models ft. Bret Taylor of Sierra
Evaluate AI product pricing and specialization around measurable outcomes rather than seat counts.
 32 minutes
32 minutesFast LLM Serving with vLLM and PagedAttention
Understand why serving engines, batching and KV-cache memory dominate self-hosted inference economics.
 56 minutes
56 minutesBuild Hour: Prompt Caching
Use prompt caching only when stable prefixes, latency and cost behavior match the workload.
 19 minutes
19 minutesIs This the End of RAG? Anthropic's NEW Prompt Caching
Walks through Anthropic's prompt caching against Gemini's context caching with concrete latency-and-cost reductions per use case (long-document chat, few-shot, multi-turn).
 17 minutes
17 minutesDefending LLM - Prompt Injection
Review prompt-injection defenses such as taint analysis, output-shape restrictions, user isolation, deterministic settings and redundant checks for critical paths.
 13 minutes
13 minutesAttacking LLM - Prompt Injection
Model prompt injection as untrusted-data mixing and design boundaries around tool use.
 5 minutes
5 minutesClaude has taken control of my computer...
Understand why screenshot-based computer use is powerful, slow, expensive and brittle compared with API-native automation.
 44 minutes
44 minutesBuilding Brain-Like Memory for AI | LLM Agent Memory Systems
A longer implementation pass through the cognitive-science-inspired categories — episodic, semantic, working, procedural — wired into an agent in code.
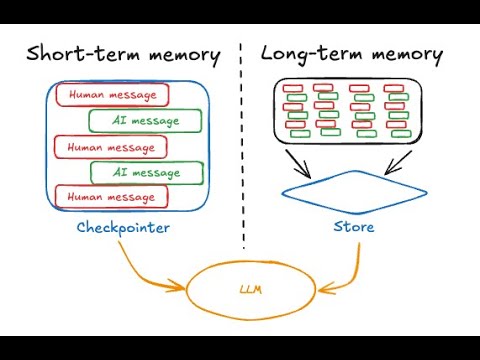 7 minutes
7 minutesMemory for agents (conceptual video)
Separate short-term and long-term memory decisions and decide when agent memory should be written.
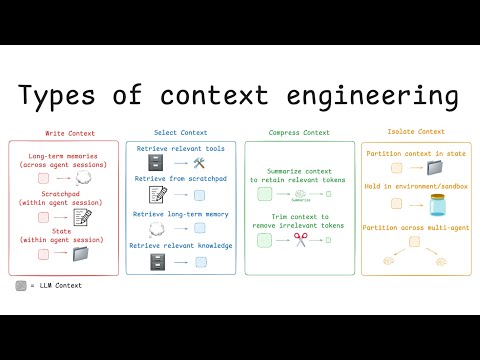 22 minutes
22 minutesContext Engineering for Agents
Apply write, select, compress and isolate patterns to manage agent context deliberately.
 8 minutes
8 minutesContext Rot: How Increasing Input Tokens Impacts LLM Performance
Understand how long context can fail under ambiguity and distractors, then design tests around that risk.
 66 minutes
66 minutesCrewAI Tutorial: Complete Crash Course for Beginners
The same kind of build, but in CrewAI's role-goal-backstory style — agents as team members, tasks as deliverables, the framework hiding the execution loop.
 190 minutes
190 minutesLangGraph Complete Course for Beginners – Complex AI Agents with Python
A long, code-along build through LangGraph's state graphs, nodes, edges, conditional routing, checkpoints, and tool use.
 18 minutes
18 minutesTips for building AI agents
Recognize common agent-building pitfalls before adding multiple agents, complex prompts or hidden state.
 15 minutes
15 minutesHow We Build Effective Agents: Barry Zhang, Anthropic
Design simpler agent loops with clear stopping rules, task boundaries and human control points.
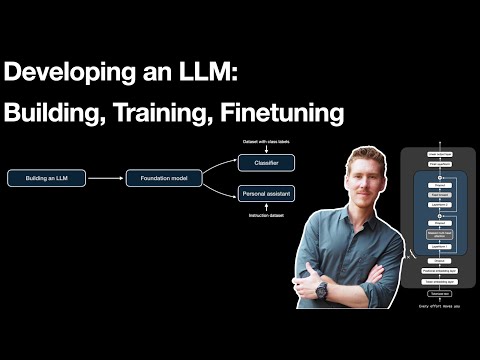 59 minutes
59 minutesDeveloping an LLM: Building, Training, Finetuning
Place fine-tuning inside the broader training pipeline and decide when it is better than prompting or RAG.
 157 minutes
157 minutesFine Tuning LLM Models – Generative AI Course
Long, theory-then-code course covering quantisation, LoRA, QLoRA, and full PEFT on Llama 2 and Gemma — on hardware most developers actually have.
 16 minutes
16 minutesGraph RAG: Improving RAG with Knowledge Graphs
Understand the Microsoft-style GraphRAG flow: entity extraction, communities, summaries and query-focused synthesis.
Showing 24 of 63