Topic
Private, Local & Self-hosted AI
Local models, private deployment patterns, self-hosted inference, and hybrid architectures.
10 stories (4 articles · 6 videos)
Start here
A few good first pieces before you browse the full feed.
 10 min read
10 min readArticle
Local AI on your Mac: Ollama, LM Studio, and what 7B models can really do
Running AI locally has matured. With Ollama or LM Studio and a modern Mac, you can run capable models offline, free, and private. What works, what doesn't, and the use cases that actually benefit.
Evaluate the implementation pattern, failure modes, and guardrails before building.
Intermediate
 10 min read
10 min readArticle
Private AI deployment patterns: local, VPC, self-hosted, and hybrid
Private AI is not one architecture. A practical comparison of local models, enterprise SaaS, VPC deployments, self-hosted inference, and hybrid patterns for SMEs that care about privacy and control.
Choose a private AI deployment pattern based on data sensitivity, capability needs, cost, latency, and operational capacity.
Advanced
 11 min read
11 min readArticle
Self-hosted vs hosted inference: vLLM, TGI, and the break-even math
At what scale does self-hosting beat API calls? The actual math, the operational realities, and the patterns that distinguish teams who should self-host from teams who should keep paying for managed inference.
Use the article as decision context for adoption, risk, governance, or investment choices.
Advanced
More in this topic
 37 minutes
37 minutesVideo
VMware Private AI Foundation Capabilities and Features Update from Broadcom
Tech Field Day. Shows private AI as layered infrastructure: controlled compute, isolated environments, Kubernetes, inference containers, model governance, self-service provisioning, GPU sharing and monitoring. That maps directly to the article's warning that privacy depends on deployment boundaries, logs, access and operations, not on the word "local."
Advanced
 13 min read
13 min readArticle
Fine-tuning in 2026: when LoRA beats RAG, and how to do it without a cluster
LoRA fine-tuning has become accessible — you can run real fine-tunes on a laptop or rent a GPU for an hour. The patterns that work, the cases where fine-tuning beats RAG, and a practical end-to-end workflow from data prep to deployment.
Evaluate the implementation pattern, failure modes, and guardrails before building.
Advanced
 32 minutes
32 minutesVideo
Fast LLM Serving with vLLM and PagedAttention
Anyscale. Walks through why naive LLM serving wastes 60–80% of GPU memory, how PagedAttention borrows OS-style paging to fix that, and why continuous batching produces the 24× throughput numbers the article uses in its math. After this, the article's "you'll be lucky to hit 50% utilisation" line stops feeling abstract.
Advanced
 59 minutes
59 minutesVideo
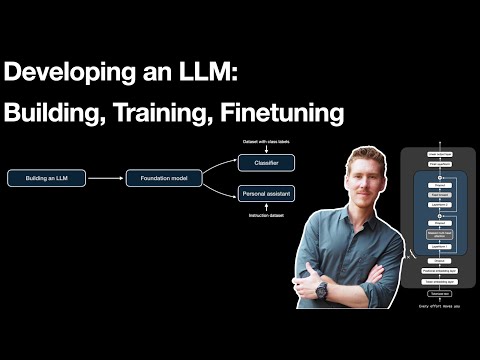
Developing an LLM: Building, Training, Finetuning
Sebastian Raschka. Sebastian Raschka's slower walkthrough of where fine-tuning sits in the broader LLM training pipeline — instruction tuning, classification fine-tuning, parameter-efficient methods, and the trade-offs the article calls out before recommending LoRA. Good calibration before you start, especially if your team is debating whether fine-tuning is even the right step.
Advanced
 157 minutes
157 minutesVideo
Fine Tuning LLM Models – Generative AI Course
freeCodeCamp.org. Long, theory-then-code course covering quantisation, LoRA, QLoRA, and full PEFT on Llama 2 and Gemma — on hardware most developers actually have. It is the closest thing to a "shadow somebody who has done this" experience on YouTube and lines up with the article's "you don't need a cluster" claim with concrete VRAM budgets.
Advanced
 6 minutes
6 minutesVideo
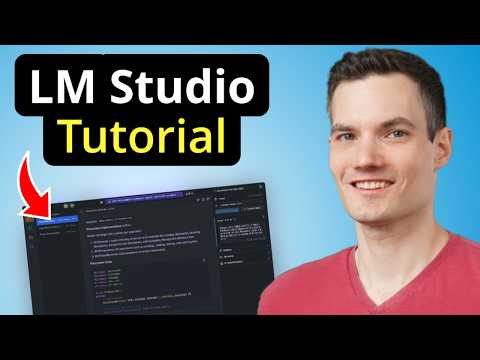
LM Studio Tutorial: Run Large Language Models (LLM) on Your Laptop
Kevin Stratvert. Same workflow as Ollama but in a GUI: download LM Studio, pull a Llama or Gemma model, chat, drop a PDF in and ask questions about it. Good for readers who'd rather not live in the terminal — also useful for getting a feel for how a 1B–3B model actually performs against a heavier one.
Intermediate
 14 minutes
14 minutesVideo
Learn Ollama in 15 Minutes - Run LLM Models Locally for FREE
Tech With Tim. A tight, no-nonsense Ollama walkthrough — install, pull a model, chat, then poke at the local HTTP API from Python and create a custom model with a Modelfile. Covers exactly the workflow the article describes for daily use on a Mac, including how to think about model size vs. your machine's RAM.
Intermediate