Curated library
Videos
Watch the clearest companion videos without browsing everything at once. Pick a path, continue where you left off, or use the filters when you know what you need.
 4 minutes
4 minutesIntroducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings
Understand why multilingual embeddings matter for private internal search and where local retrieval can reduce data-exposure risk.
 32 minutes
32 minutesHow to Build Human-Centered AI Workflows in Localization with Shashi Bhushan
Learn how to introduce AI into localization without removing human ownership of meaning, tone, terminology and final approval.
 18 minutes
18 minutesAWS re:Invent 2025 - Implementing Human-in-the-Loop Controls for Multi-Agent AI Systems (CNS428)
See how approval gates can be implemented as explicit workflow checkpoints rather than informal manual review after something goes wrong.
 17 minutes
17 minutes12-Factor Agents: Patterns of reliable LLM applications — Dex Horthy, HumanLayer
Learn how to design AI workflows that can pause, resume, ask for human judgment and keep business state separate from model guesses.
 7 minutes
7 minutesUnlock Better RAG & AI Agents with Docling
Understand why document parsing, structure preservation and ingestion quality gates matter before building RAG over PDFs and mixed file formats.
 59 minutes
59 minutesFrom Hype to Habit: How Tech Companies Are Scaling AI Beyond the Experimental
Connect AI adoption maturity to workflow-level measurement, governance, operating health and sustained behavior change.
 41 minutes
41 minutesPrivate AI vs. Cloud: How Enterprise Leaders Can Make Smarter Build-or-Buy Decisions
Make AI build-vs-buy decisions around outcome, data control, workload economics, infrastructure readiness and operational ownership.
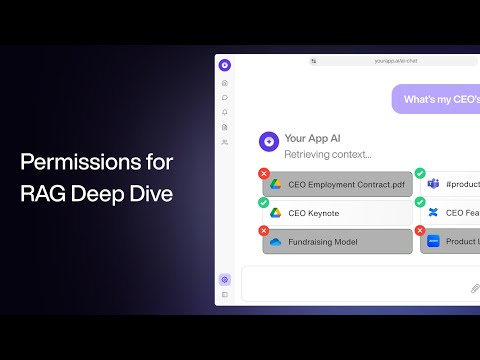 20 minutes
20 minutesPermissions & Access Control for RAG - a Deep Dive Tutorial
Evaluate practical access-control patterns for company knowledge RAG before indexing sensitive internal documents.
 48 minutes
48 minutesHow to Build Reliable AI Agents (Context + Evals Explained) | Tobias Leong, Axium
Design AI workflows around context, evals and observability so production failures can be named, measured and fixed.
 35 minutes
35 minutesAI Code Generation: Wins, Fails and the Future
Build a realistic mental model for when repository-aware coding agents help and where senior engineering control is still required.
 37 minutes
37 minutesVMware Private AI Foundation Capabilities and Features Update from Broadcom
Evaluate private AI as an infrastructure and governance decision instead of defaulting to either SaaS or self-hosting by instinct.
 6 minutes
6 minutesAI Voice Agents: How They Actually Work & Why They Sound So Human
Recognize the core architecture of a voice agent and the failure points that affect customer trust in real calls.
 33 minutes
33 minutesThe AI Engineer's Guide to Surviving the EU AI Act
Understand why AI Act readiness depends on practical AI system inventory, data governance, engineering controls and operational ownership.
 42 minutes
42 minutesVertical AI Agents Could Be 10X Bigger Than SaaS
Assess when vertical AI agents create real defensibility and when they are only thin wrappers.
 34 minutes
34 minutesHow AI is Reinventing Software Business Models ft. Bret Taylor of Sierra
Evaluate AI product pricing and specialization around measurable outcomes rather than seat counts.
 32 minutes
32 minutesFast LLM Serving with vLLM and PagedAttention
Understand why serving engines, batching and KV-cache memory dominate self-hosted inference economics.
 56 minutes
56 minutesBuild Hour: Prompt Caching
Use prompt caching only when stable prefixes, latency and cost behavior match the workload.
 19 minutes
19 minutesIs This the End of RAG? Anthropic's NEW Prompt Caching
Walks through Anthropic's prompt caching against Gemini's context caching with concrete latency-and-cost reductions per use case (long-document chat, few-shot, multi-turn).
 17 minutes
17 minutesDefending LLM - Prompt Injection
Review prompt-injection defenses such as taint analysis, output-shape restrictions, user isolation, deterministic settings and redundant checks for critical paths.
 13 minutes
13 minutesAttacking LLM - Prompt Injection
Model prompt injection as untrusted-data mixing and design boundaries around tool use.
 8 minutes
8 minutesAnthropic's Claude Computer Use Is A Game Changer | YC Decoded
Decide where browser or computer-use agents might be commercially useful despite their operational risk.
 5 minutes
5 minutesClaude has taken control of my computer...
Understand why screenshot-based computer use is powerful, slow, expensive and brittle compared with API-native automation.
 44 minutes
44 minutesBuilding Brain-Like Memory for AI | LLM Agent Memory Systems
A longer implementation pass through the cognitive-science-inspired categories — episodic, semantic, working, procedural — wired into an agent in code.
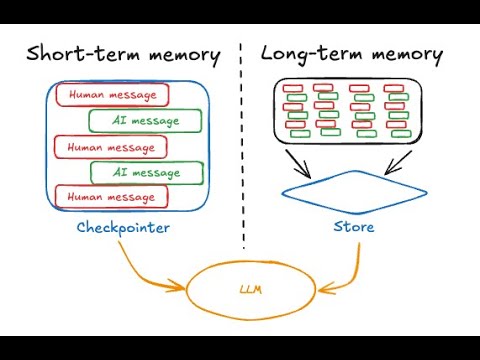 7 minutes
7 minutesMemory for agents (conceptual video)
Separate short-term and long-term memory decisions and decide when agent memory should be written.
Showing 24 of 157
Freshly reviewed
Recently checked videos and companion picks from the AI Expert library.
Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings
Understand why multilingual embeddings matter for private internal search and where local retrieval can reduce data-exposure risk.
How to Build Human-Centered AI Workflows in Localization with Shashi Bhushan
Learn how to introduce AI into localization without removing human ownership of meaning, tone, terminology and final approval.
AWS re:Invent 2025 - Implementing Human-in-the-Loop Controls for Multi-Agent AI Systems (CNS428)
See how approval gates can be implemented as explicit workflow checkpoints rather than informal manual review after something goes wrong.