Teema
Privaatne, kohalik ja ise majutatud AI
Kohalikud mudelid, privaatse juurutuse mustrid, ise majutatud käitus ja hübriidarhitektuurid.
10 lugu (4 artiklit · 6 videot)
Alusta siit
Mõned head esimesed materjalid enne kogu voo sirvimist.
 10 min lugemist
10 min lugemistArtikkel
Kohalik AI sinu Macis: Ollama, LM Studio ja see, mida 7B mudelid tegelikult suudavad
AI lokaalne käivitamine on küpsenud. Ollama või LM Studio ja moodsa Maciga saad jooksutada võimekaid mudeleid offline'is, tasuta ja privaatselt. Mis töötab, mis mitte ja millised kasutusjuhud sellest tegelikult kasu saavad.
Hinda lahendusmustrit, tõrkeviise ja kaitsepiirdeid enne päris töövoo ehitamist.
Edasijõudnud
 10 min lugemist
10 min lugemistArtikkel
Privaatse AI juurutusmustrid: lokaalne, VPC, ise hostitud ja hübriid
Privaatne AI ei ole üks arhitektuur. Praktiline võrdlus lokaalsete mudelite, ettevõtte SaaS-i, VPC juurutuste, ise hostitud inference'i ja hübriidmustrite vahel privaatsust ja kontrolli vajavatele VKE-dele.
Valid privaatse AI juurutusmustri andmete tundlikkuse, võimekusvajaduse, kulu, latentsuse ja operatsioonilise võimekuse põhjal.
Ekspert
 11 min lugemist
11 min lugemistArtikkel
Ise hostitud vs hallatud inferents: vLLM, TGI ja tasuvuspiiri matemaatika
Millise mastaabi juures võidab ise hostimine API-kõnesid? Tegelik matemaatika, operatiivsed reaalsused ja mustrid, mis eristavad tiime, kes peaksid ise hostima, neist, kes peaksid hallatud inferentsi eest edasi maksma.
Arvutad, millal ise hostitud inferents võib hallatud API-dest parem olla, ja hindad realistlikult operatsioonilist koormust.
Ekspert
Veel selles teemas
 37 minutit
37 minutitVideo
VMware Private AI Foundationi võimekused ja uuendused Broadcomilt
Tech Field Day. Näitab privaatset AI-d kihilise infrastruktuurina: kontrollitud arvutus, eraldatud keskkonnad, Kubernetes, inferentsikonteinerid, mudelihaldus, iseteenindus, GPU jagamine ja monitooring. See sobib artikli hoiatusega, et privaatsus sõltub piiridest, logidest, ligipääsust ja operatsioonidest, mitte sõnast "lokaalne".
Ekspert
 13 min lugemist
13 min lugemistArtikkel
Peenhäälestus 2026. aastal: millal LoRA võidab RAG-i ja kuidas seda teha ilma klastrita
LoRA-põhine peenhäälestus on muutunud väikestele tiimidele kättesaadavamaks. Millal peenhäälestus võidab RAG-i, millised mustrid töötavad ja milline on praktiline töövoog andmete ettevalmistamisest juurutamiseni.
Hindad, millal peenhäälestus on vajalik, milliseid andmeid see nõuab ja kuidas vältida kallist lahendust vales probleemis.
Ekspert
 32 minutit
32 minutitVideo
Kiire LLM-serveerimine vLLM-i ja PagedAttentioniga
Anyscale. Käib läbi, miks naiivne LLM-serveerimine raiskab 60–80% GPU mälust, kuidas PagedAttention laenab OS-i stiilis pagineerimist seda parandama ja miks pidev batching toodab 24× läbilaskvuse numbreid, mida artikkel oma matemaatikas kasutab. Pärast seda lakkab artikli "õnneks tabad 50% kasutusastet" rida abstraktne olemast.
Ekspert
 59 minutit
59 minutitVideo
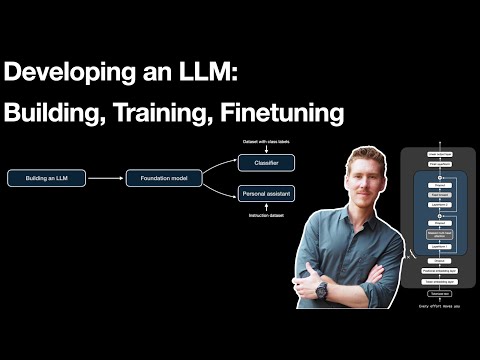
LLM-i arendamine: ehitamine, treenimine, finetuning
Sebastian Raschka. Sebastian Raschka aeglasem läbikäik sellest, kus fine-tuning laiemas LLM-treeningu konveieris istub — instruction tuning, klassifikatsiooni fine-tuning, parameetri-tõhusad meetodid ja kompromissid, mida artikkel välja toob enne LoRA soovitamist. Hea kalibreerimine enne alustamist, eriti kui su tiim arutleb, kas fine-tuning on üldse õige samm.
Ekspert
 157 minutit
157 minutitVideo
LLM-mudelite fine-tuning – generatiivse AI kursus
freeCodeCamp.org. Pikk, teooria-siis-kood kursus, mis katab kvantiseerimise, LoRA, QLoRA ja täis-PEFTi Llama 2 ja Gemma peal — riistvaral, mis enamikul arendajatel päriselt olemas on. See on YouTube'is kõige lähemal "vaata üle õla kellelegi, kes seda teinud on" kogemusele ja sobib artikli "sul pole vaja klastrit" väitega koos konkreetsete VRAM-eelarvetega.
Ekspert
 6 minutit
6 minutitVideo
LM Studio õpetus: käivita suuri keelemudeleid (LLM) oma sülearvutil
Kevin Stratvert. Sama töövoog mis Ollama, aga GUI-s: laadi LM Studio alla, tõmba Llama või Gemma mudel, vestle, kukuta PDF sisse ja küsi selle kohta küsimusi. Hea lugejatele, kes pigem terminalis ei elaks — kasulik ka selle jaoks, et saada tunnetus, kuidas 1B–3B mudel raskema vastu päriselt esineb.
Edasijõudnud
 14 minutit
14 minutitVideo
Õpi Ollama selgeks 15 minutiga - käivita LLM mudeleid lokaalselt TASUTA
Tech With Tim. Tihke, asjalik Ollama läbikäik — paigaldus, mudeli tõmbamine, vestlus, siis lokaalse HTTP API torkimine Pythonist ja kohandatud mudeli loomine Modelfile'iga. Katab täpselt selle töövoo, mida artikkel Macis igapäevaseks kasutamiseks kirjeldab, sealhulgas kuidas mõelda mudeli suurusest vs su masina RAM-i kohta.
Edasijõudnud