Kiire LLM-serveerimine vLLM-i ja PagedAttentioniga
Anyscale. Käib läbi, miks naiivne LLM-serveerimine raiskab 60–80% GPU mälust, kuidas PagedAttention laenab OS-i stiilis pagineerimist seda parandama ja miks pidev batching toodab 24× läbilaskvuse numbreid, mida artikkel oma matemaatikas kasutab. Pärast seda lakkab artikli "õnneks tabad 50% kasutusastet" rida abstraktne olemast.
AI Experti märkus
Mudelite nimed, hinnad ja võimekused muutuvad kiiresti. Kasuta videot otsustusmustri mõistmiseks ning kontrolli praegust mudelikäitumist enne kasutuselevõttu.
Mida sellest videost kaasa võtta
Saad tehnilise mustri teemal "Ise-hostitud vs hostitud inference" ning oskad hinnata riske, piire ja järgmist sammu.
Mida enne vaadata või teada
Kasuks tuleb arusaam API-dest, automatsioonidest, RAG-ist või agentide tööpõhimõtetest.
Järgmisena vaata
Jätka sama õpiteekonda järgmiste hoolikalt valitud kaasvideotega.
 42 minutit
42 minutitVertikaalsed AI-agendid võivad olla 10X SaaS-ist suuremad
Saad tehnilise mustri teemal "LLM-toote välja saatmine" ning oskad hinnata riske, piire ja järgmist sammu.
Vaata järgmist 48 minutit
48 minutitKuidas ehitada usaldusväärseid AI agente: kontekst ja evalid
Disainida AI töövooge konteksti, evalide ja observability ümber, nii et tootmisvead oleksid nimetatavad, mõõdetavad ja parandatavad.
Vaata järgmist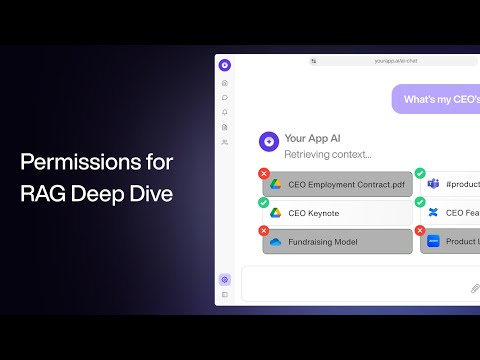 20 minutit
20 minutitRAG-i õigused ja ligipääsukontroll: süvitsi õpetus
Hinnata praktilisi ligipääsukontrolli mustreid ettevõtte teadmiste RAG-i jaoks enne tundlike sisemiste dokumentide indekseerimist.
Vaata järgmist