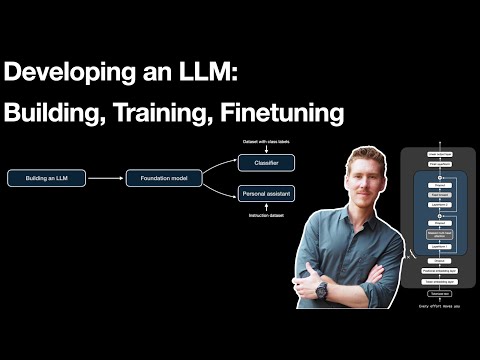
Fast LLM Serving with vLLM and PagedAttention
Anyscale. Проходит, почему наивный LLM-serving тратит впустую 60–80% памяти GPU, как PagedAttention заимствует пейджинг в стиле OS, чтобы это починить, и почему continuous batching даёт те самые 24× по throughput, на которые опирается арифметика статьи. После этого фраза статьи «вам повезёт попасть в 50% утилизации» перестаёт казаться абстрактной.
Заметка AI Expert
Названия моделей, цены и возможности быстро меняются. Используйте видео для понимания принципа выбора, затем проверьте актуальное поведение модели перед внедрением.
Что вынести из этого видео
Оценить архитектурный подход, возможные сбои и защитные меры до разработки.
Что посмотреть или знать заранее
Полезно понимать API, автоматизации, RAG или базовую архитектуру агентов.
Смотреть дальше
Продолжайте тот же учебный путь со следующими связанными видео.
 42 мин
42 минVertical AI Agents Could Be 10X Bigger Than SaaS
Оценить архитектурный подход, возможные сбои и защитные меры до разработки.
Смотреть дальше 48 мин
48 минКак строить надёжных AI-агентов: контекст и evals
Проектировать рабочие процессы с ИИ вокруг контекста, оценок качества и наблюдаемости, чтобы сбои в продакшене можно было назвать, измерить и исправить.
Смотреть дальше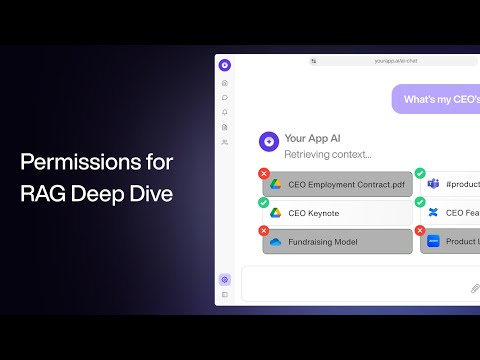 20 мин
20 минПрава и access control для RAG: глубокий tutorial
Оценить практические паттерны контроля доступа для RAG по знаниям компании перед индексацией чувствительных внутренних документов.
Смотреть дальше