Loading
 42 minutit
42 minutitVertikaalsed AI-agendid võivad olla 10X SaaS-ist suuremad
Saad tehnilise mustri teemal "LLM-toote välja saatmine" ning oskad hinnata riske, piire ja järgmist sammu.
Vaata järgmistAnyscale. Käib läbi, miks naiivne LLM-serveerimine raiskab 60–80% GPU mälust, kuidas PagedAttention laenab OS-i stiilis pagineerimist seda parandama ja miks pidev batching toodab 24× läbilaskvuse numbreid, mida artikkel oma matemaatikas kasutab. Pärast seda lakkab artikli "õnneks tabad 50% kasutusastet" rida abstraktne olemast.
Mudelite nimed, hinnad ja võimekused muutuvad kiiresti. Kasuta videot otsustusmustri mõistmiseks ning kontrolli praegust mudelikäitumist enne kasutuselevõttu.
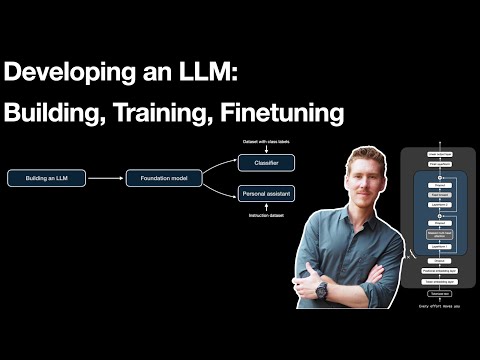
Saad tehnilise mustri teemal "Ise-hostitud vs hostitud inference" ning oskad hinnata riske, piire ja järgmist sammu.
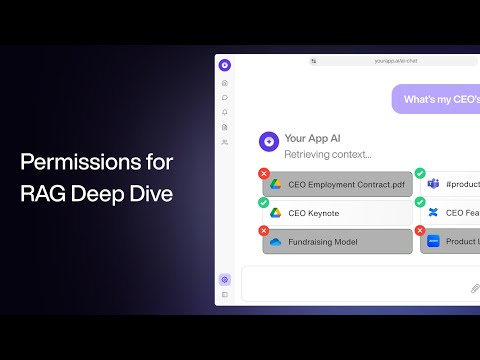
Kasuks tuleb arusaam API-dest, automatsioonidest, RAG-ist või agentide tööpõhimõtetest.
Jätka sama õpiteekonda järgmiste hoolikalt valitud kaasvideotega.